Consider the following problem:
Framing the Problem
Before diving into the problem, I think that it is worth pausing to consider a few possible constraints or follow-ups to the problem. For example: what if we only care about the median of the last elements? What if deletions need to be supported as well? Asking questions like these beforehand can shift your perspective and often leads to more flexible, extendable solutions.
Now, to solve this problem, let's begin by black-boxing the two operations we need to support. We don’t need to immediately know how the data structure works internally, only what guarantees it should provide. At a high level, our black box must satisfy two contracts:
- insert(int num): place a new number into the structure in such a way that we can still access the median quickly.
- median(): return the middle value(s) of the current set of numbers in constant time.
Thinking about it this way highlights an important point: although the median is defined in terms of a fully sorted list, we don’t actually need the entire list sorted at all times. We only need to keep enough information to recover the middle value(s) quickly. I think that for problem, especially, its incredibly useful to think about only what is minimally necessary to satisfy the problem constraints.
Continuing with our black-box abstraction, we must consider next what properties we want our black box need to expose. I think that the following list encapsulates the key properties we want:
- Efficiency: Insertions should not degenerate into re-sorting the entire dataset.
- Balance: The data structure should maintain a balance between the lower and upper halves of the dataset to ensure quick access to the median.
- Accessibility: We don’t care about arbitrary lookups. We only need the “boundary” elements where the lower and upper halves meet.
Once framed this way, the solution becomes much more apparent: instead of treating the structure as one ordered list of elements, we can represent it as two sorted halves, using a container for the smaller elements and a container for the larger elements. The median then sits in the middle where the two halves meet. Here's an illustration to enforce the idea:
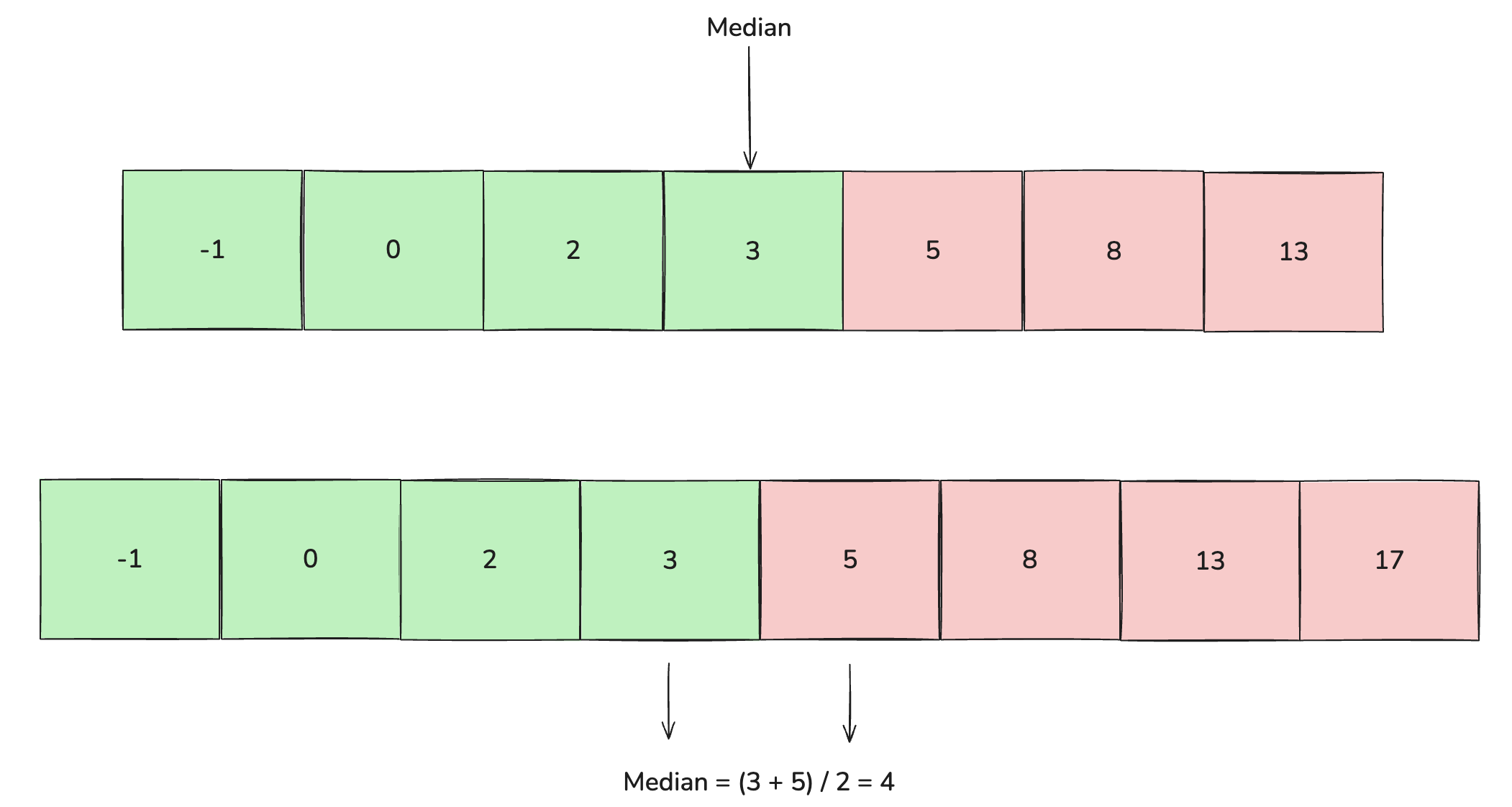
Median in odd and even length lists
Now that we have a clear idea of how to structure our data, the problem is no longer "how do we keep an entire dataset sorted?" but rather "how do we maintain two balanced halves and ensure the seam between them remains intact?" This is a far easier task.
The Two-Heap Solution
To achieve this, we can use two heaps: a max-heap for the lower half and a min-heap for the upper half. The max-heap gives us instant access to the largest element of the lower half, and the min-heap gives us instant access to the smallest element of the upper half. By carefully rebalancing after each insertion, we ensure the two heaps differ in size by at most one element, meaning that the median is always available in constant time: either the top of the larger heap or the average of the two tops if they are balanced.
One subtlety we need to address in this approach is how to keep the two heaps balanced, ensuring that their sizes differ by at most one element. If the total number of elements is even, both heaps should contain the same number of items. If the total is odd, we can allow one heap (say, the lower half, without loss of generality) to hold a single extra element. With this invariant in place, the median will always be easy to retrieve: either it is the top of the larger heap, or, when the heaps are the same size, the average of their two tops. After every insertion, we check the sizes of the heaps and rebalance them if necessary by moving the top element from one heap to the other.
Supporting Deletions
I will avoid going into the full implementation details here, it is left as an exercise to the reader. What I do want to do, however, is return to the follow-up questions I raised at the beginning. In particular: what if we also want to delete elements from the stream? Right away, we hit a challenge. Standard heaps are great for fast insertions and retrieving the top element, but they do not support efficient arbitrary lookups, let alone deletions. So, how do we adapt while keeping our solution efficient?
Being lazy is surprisingly the answer here. Instead of immediately removing an element when a deletion is requested, we can simply mark it as "deleted" in a separate data structure, say a hash set. Then, whenever we access the top of a heap, either to retrieve the median or to rebalance, we check whether that element has been marked as deleted. If it has, we discard it and move to the next element. We repeat this until the top of the heap is “clean.”
This strategy pushes the cost of deletions onto the moments when we actually need the heap tops, rather than every time a deletion is requested. The result is that insertions and deletions remain logarithmic on average, while median queries stay constant-time. It’s a simple idea, but an elegant example of how we can make an otherwise intractable problem efficient.
Here's a link to the problem on LeetCode if you want to try it out yourself: LeetCode: Find Median From Data Stream.